Intro
To better address the needs for real-time streaming data storage and processing in various businesses, we (EMQ) have been searching for an optimal system and architecture.
We have presented a brand new concept in the previous post “When Database Meets Stream Computing: The Birth of Streaming Database!” - “Streaming Database” - a new database category. In the article today, we will introduce HStreamDB, a Streaming Database currently being developed by the Haskell Team from EMQ. Comparing it with the existing unstructured streaming solutions, we believe that Streaming Database pioneered by HStreamDB will be the best choice in the era of real-time data processing. Also that it will become the core infrastructure of software systems in the future.
HStream Streaming Database Overview
HStreamDB is a streaming database designed for streaming data, with complete lifecycle management for accessing, storing, processing, and distributing large-scale real-time data streams. It uses standard SQL (and its stream extensions) as the primary interface language, with real-time as the main feature, and aims to simplify the operation and management of data streams and the development of real-time applications.
The figure below shows the overall architecture of HStreamDB. A single HStreamDB node consists of two core components, HStream Server (HSQL) and HStream Storage (HStorage). And an HStream cluster consists of several peer-to-peer HStreamDB nodes. Clients can connect to any HStreamDB node in the cluster and perform stream processing and analysis through your familiar SQL language.
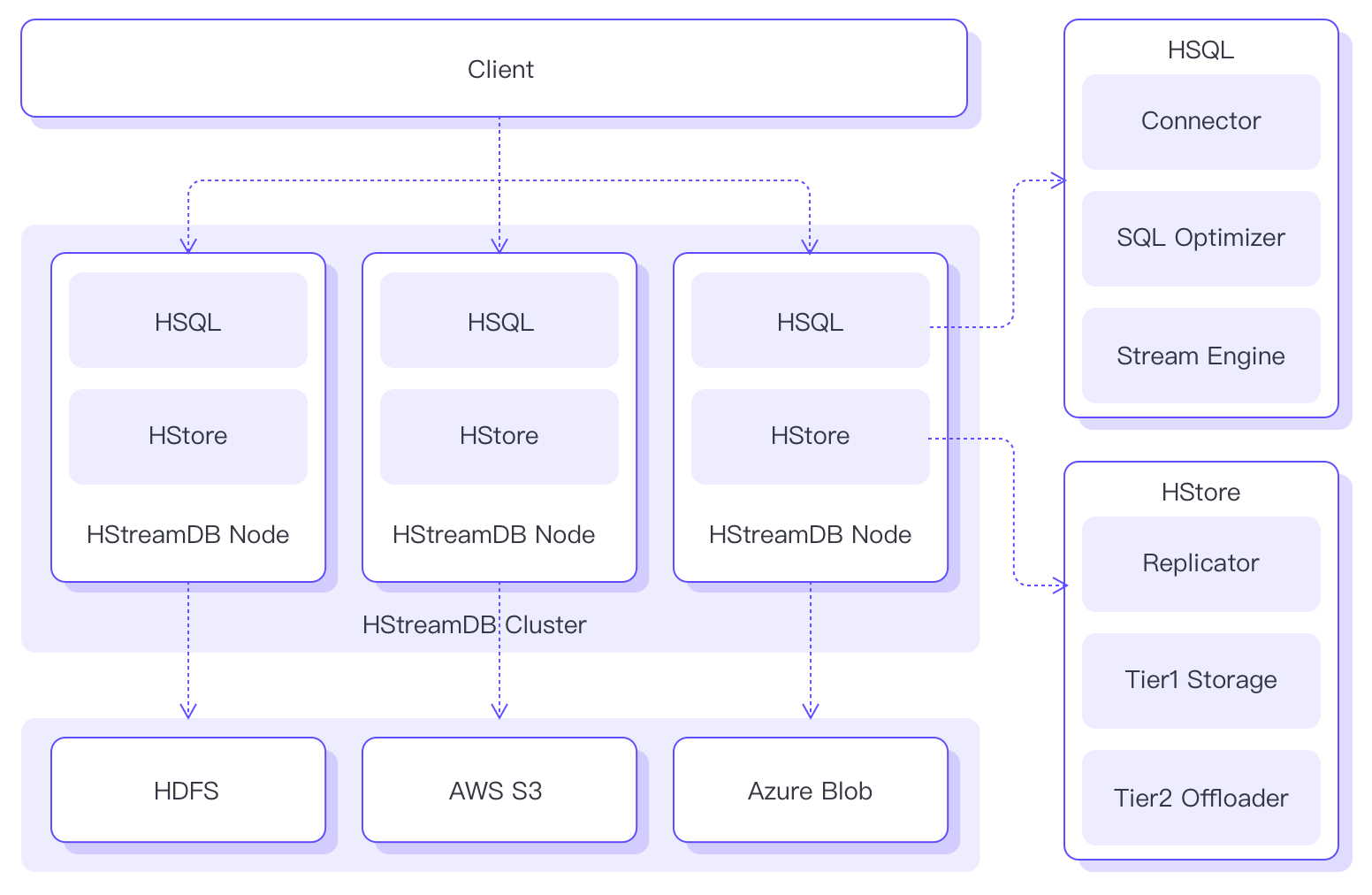
HStream Server (HSQL), the core computation component of HStreamDB, is designed to be stateless. The primary responsibility of HSQL is to support client connection management, security authentication, SQL parsing and optimization, and operations for stream computation such as task creation, scheduling, execution, management, etc.
HStream Server
HStream Server (HSQL) top-down layered structures:
- Access Layer
It is in charge of protocol processing, connection management, security authentication, and access control for client requests.
- SQL layer
To perform most stream processing and real-time analysis tasks, clients interact with HStreamDB through SQL statements. This layer is mainly responsible for compiling these SQL statements into logical data flow diagrams. Like the classic database system model, it contains two core sub-components: SQL parser and SQL optimizer. The SQL parser deals with the lexical and syntactic analysis and the compilation from SQL statements to relational algebraic expressions; the SQL optimizer will optimize the generated execution plan based on various rules and contexts.
- Stream Layer
Stream layer includes the implementation of various stream processing operators, the data structures and DSL to express data flow diagrams, and the support for user-defined functions as processing operators. So, it is responsible for selecting the corresponding operator and optimization to generate the executable data flow diagram.
- Runtime Layer
It is the layer responsible for executing the computation task of data flow diagrams and returning the results. The main components of the layer include task scheduler, state manager, and execution optimizer. The schedule takes care of the tasks scheduling between available computation resources, such as multiple threads of a single process, multiple processors of a single machine, and multiple machines or containers of a distributed cluster.
HStream Storage (HStore), the core storage component of HStreamDB, is a low-latency storage component explicitly designed for streaming data. It can store large-scale real-time data in a distributed and persistent manner and seamlessly interface with large-capacity secondary storage such as S3 through the Auto-Tiering mechanism to achieve unified storage of historical and real-time data.
The core storage model of HStore is a logging model that fits with streaming data. Regard data stream as an infinitely growing log, the typical operations supported include appending and reading by batches. Also, since the data stream is immutable, it generally does not support update operations.
HStream Storage (HStore)
HStream Storage (HStore) consists of following layers
Streaming Data API layer
This layer provides the core data stream management and read/write operations, including stream creation/deletion and writing to/consuming data in the stream. In the design of HStore, data streams are not stored as actual streams. Therefore, the creation of a stream is a very light-weight operation. There is no limit to the number of streams to be created in HStore. Besides, it supports concurrent writes to numerous data streams and still maintains a stable low latency. For the characteristics of data streams, HStore provides append operation to support fast data writing. While reading from stream data, it gives a subscription-based operation and pushes any new data written to the stream to the data consumer in real time.
Replicator Layer
This layer implements the strongly consistent replication based on an optimized Flexible Paxos consensus mechanism, ensuring the fault tolerance and high availability to data, and maximizes cluster availability through a non-deterministic data distribution policy. Moreover, it supports replication groups reconfiguration online to achieve seamless cluster data balancing and horizontal scaling.
Tier1 Local Storage Layer
The layer fulfilled local persistent storage needs of data based on the optimized RocksDB storage engine, which encapsulates the access interface of streaming data and can support low-latency writing and reading a large amount of data.
Tier2 Offloader Layer
This layer provides a unified interface encapsulation for various long-term storage systems, such as HDFS, AWS S3, etc. It supports automatic offloading of historical data to these secondary storage systems and can also be accessed through a unified streaming data interface.
HStreamDB Functional Architecture
Note: The following features the milestone of HStreamDB version 1.0. Some features are under continuous development and not yet fully implemented in the current version. Please stay tuned.
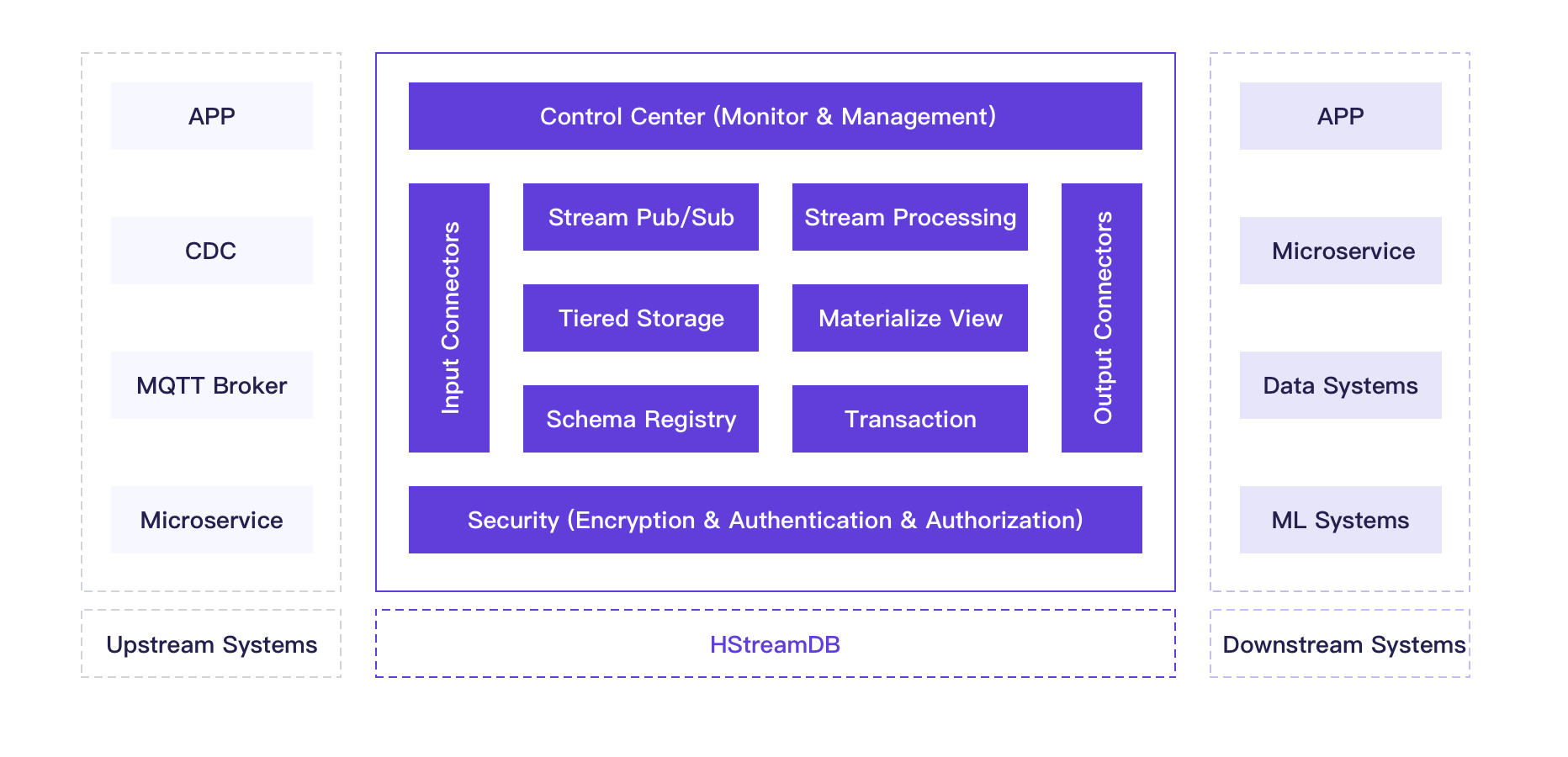
Streaming data processing via SQL
HStreamDB has designed a complete processing solution based on event time. It supports basic filtering and conversion operations, aggregations by key, calculations based on various time windows, joining between data streams, and processing disordered and late messages to ensure the accuracy of calculation results. Simultaneously, the stream processing solution of HStream is highly extensible, and users can extend the interface according to their own needs.
Materialized View
HStreamDB will offer materialized view to support complex query and analysis operations on continuously updated data streams. The incremental computing engine updates the materialized view instantly according to the changes of data streams, and users can query the materialized view through SQL statements to get real-time data insights.
Data Stream Management
HStreamDB supports the creation and management of large data streams. The creation of a data stream is a very light-weight operation based on an optimized storage design. It is possible to maintain a stable read/write latency in the case of many concurrent reads and writes.
Persistent storage
HStreamDB provides low latency and reliable data stream storage. It ensures that written data messages are not lost and can be consumed repeatedly. HStreamDB replicates written data messages to multiple storage nodes for high availability and fault tolerance and supports dumping cold data to lower-cost storage services, such as object storage, distributed file storage, etc. This means the storage capacity can be infinitely scalable and achieve permanent storage of data.
Schema Management of Data Streams
HStreamDB emphasizes flexible schema support. Data streams can be schema-less or schema-ed by JSON, Avro, Protobuf, etc. It will support schema evolution and automatically manages the compatibility between multiple versions of schemas.
Data streams access and distribution
Connector deals with access and distribution of HStreamDB data. They connect to various data systems, including MQTT Broker, MySQL, ElasticSearch, Redis, etc., facilitating integration with external data systems for users.
Security Mechanism
The security will be ensured by TLS encrypted transport and OAuth and JWT based authentication and authorization mechanism. The security plug-in interface is reserved for users to extend the default security mechanisms as needed.
Monitoring and O&M tools
We will set up a web-based console with system dashboards and visual charts, enabling detailed monitoring of cluster machine status, system key indicators, etc., which make it more convenient for O&M staff to manage the cluster.
Applications of HStreamDB
Real-time data analysis
Traditional data analysis usually uses batch processing techniques, which generally run on a limited pre-collected data set and have high latency. The results are often not up-to-date. In contrast, HStreamDB can analyze real-time data streams and update the results on the fly. Therefore, it can better support applications such as real-time prediction of website user activity and real-time IoT sensor data analysis. This provides more real-time data insight and avoids the error-prone and complexity of periodically scheduling in batch processing.
Event-driven applications
In Event-driven applications, actions or behaviors are triggered in real time by incoming events. These events can be stateless or stateful, such as real-time fraud detection in financial transactions, early warning during business process monitoring, IoT rules engine, etc. With HStreamDB, the implementation of these complex event-driven applications may only require a few SQL statements. The cost of developing and maintaining these applications will be significantly reduced.
Real-time Data Pipeline
It often requires a complete set of ETL systems for synchronizing and migrating data between multiple data systems, such as copying data from an online transactional database to an offline data warehouse for analysis, which is expensive to develop and maintain. Their data synchronization is often not real-time or scalable. HStreamDB integrates with various external system connectors, quickly building a real-time data pipeline to realize real-time index and cache building and other data synchronization tasks.
Online Machine Learning
Nowadays, machine learning systems play an increasingly important role in business systems, including search, recommendation, risk control, and other events that rely extensively on machine learning systems. However, with the explosion of online business and related application use cases, conventional offline systems and machine learning platforms can no longer meet business development requirements. HStreamDB’s real-time computing engine can help machine learning systems to meet online feature extraction and real-time recommendation in real time.
HStreamDB Quickstart with Docker
Pull docker images
docker pull hstreamdb/logdevice
docker pull hstreamdb/hstreamStart a local standalone HStream-Server in Docker
Create a directory for storing DB data
mkdir ./dbdataStart local logdevice cluster
docker run -td --rm --name some-hstream-store -v dbdata:/data/store --network host hstreamdb/logdevice ld-dev-cluster --root /data/store --use-tcpStart HStreamDB Server
docker run -it --rm --name some-hstream-server -v dbdata:/data/store --network host hstreamdb/hstream hstream-server --port 6570 -l /data/store/logdevice.confStart HStreamDB CLI
docker run -it --rm --name some-hstream-cli -v dbdata:/data/store --network host hstreamdb/hstream hstream-client --port 6570If everything works fine, you will enter an interactive CLI and see help information like:
Start HStream-Cli!
Command
:h help command
:q quit cli
show queries list all queries
terminate query <taskid> terminate query by id
terminate query all terminate all queries
<sql> run sql
>Create a stream
What we are going to do first is create a stream by CREATE STREAM query.
The FORMAT parameter after WITH specifies the format of data in the stream. Note that only JSON format is currently supported.
CREATE STREAM demo WITH (FORMAT = "JSON");Copy and paste this query into the interactive CLI session, and press enter to execute the statement. If everything works fine, you will get something like:
Right
( CreateTopic
{ taskid = 0
, tasksql = "CREATE STREAM demo WITH (FORMAT = "JSON");"
, taskStream = "demo"
, taskState = Finished
, createTime = 2021 - 02 - 04 09 : 07 : 25.639197201 UTC
}
)Which means the query is successfully executed.
Run a continuous query over the stream
Now we can run a continuous query over the stream we just created by SELECT query.
The query will output all records from the demo stream whose humidity is above 70 percent.
SELECT * FROM demo WHERE humidity > 70 EMIT CHANGES;It seems that nothing happened. But do not worry because there is no data in the stream now. Next, we will fill the stream with some data so the query can produce the output we want. Besides, please note that this SELECT is different from SELECT in other databases. The command will execute until explicitly terminated.
Start another CLI session
docker exec -it some-hstream-cli hstream-client --port 6570Insert data into the stream
Run each of the given INSERT query in the new CLI session:
INSERT INTO demo (temperature, humidity) VALUES (22, 80);
INSERT INTO demo (temperature, humidity) VALUES (15, 20);
INSERT INTO demo (temperature, humidity) VALUES (31, 76);
INSERT INTO demo (temperature, humidity) VALUES ( 5, 45);
INSERT INTO demo (temperature, humidity) VALUES (27, 82);
INSERT INTO demo (temperature, humidity) VALUES (28, 86);If everything works fine, the continuous query will output matching records in real time:
{"temperature":22,"humidity":80}
{"temperature":31,"humidity":76}
{"temperature":27,"humidity":82}
{"temperature":28,"humidity":86}HStreamDB Open-source Community
As an open-source software company, EMQ always believes in the value and power of open source. Therefore, HStreamDB is open-sourced on GitHub ever since the beginning of the project.
HStreamDB is currently under development by our team, and this is an excellent opportunity and time for developers to get involved with the community.
We sincerely invite you to join us building the HStreamDB open source community. You can learn more about project from HStreamDB official website, or GitHub Repo. It is also welcomed to join the discussion on our Slack Channel. We will also host periodic open days to share the project progress and exchange technical insights.
HStreamDB will support and improve the distributed processing, Schema management, SQL optimization, monitoring and operation, and maintenance in the upcoming releases.
We believe that with the support from everyone who loves open source, we will create and witness the future of streaming databases together, starting from HStreamDB!